
I’ve been watching the user simulation space for a while now, and honestly, most LLM-based simulators feel like they’re cosplaying as humans rather than actually behaving like them. Google Research’s new ConvApparel paper finally puts numbers on what many of us suspected: these simulators have a serious realism gap.
The core problem is straightforward. We train conversational AI agents, and we need to test them. Live human testing is gold standard but expensive and slow. So the industry turned to LLM-based user simulators—agents instructed to roleplay as human users. The idea is sound, but execution has been shaky.
Think about it this way: most LLMs are trained to be helpful, polite, and knowledgeable. When you ask one to play a frustrated, impatient user who doesn’t know the product catalog, it’s like asking a ballet dancer to play a clumsy oaf. They can try, but the training fights against them.
The realism gap in plain English
What does this look like in practice? Simulators tend to be:
- Excessively verbose (real humans don’t write paragraphs)
- Too patient (real users abandon conversations after one bad turn)
- Unrealistically knowledgeable (they “know” the product catalog by heart)
- Lacking in consistent persona (they shift personality mid-conversation)
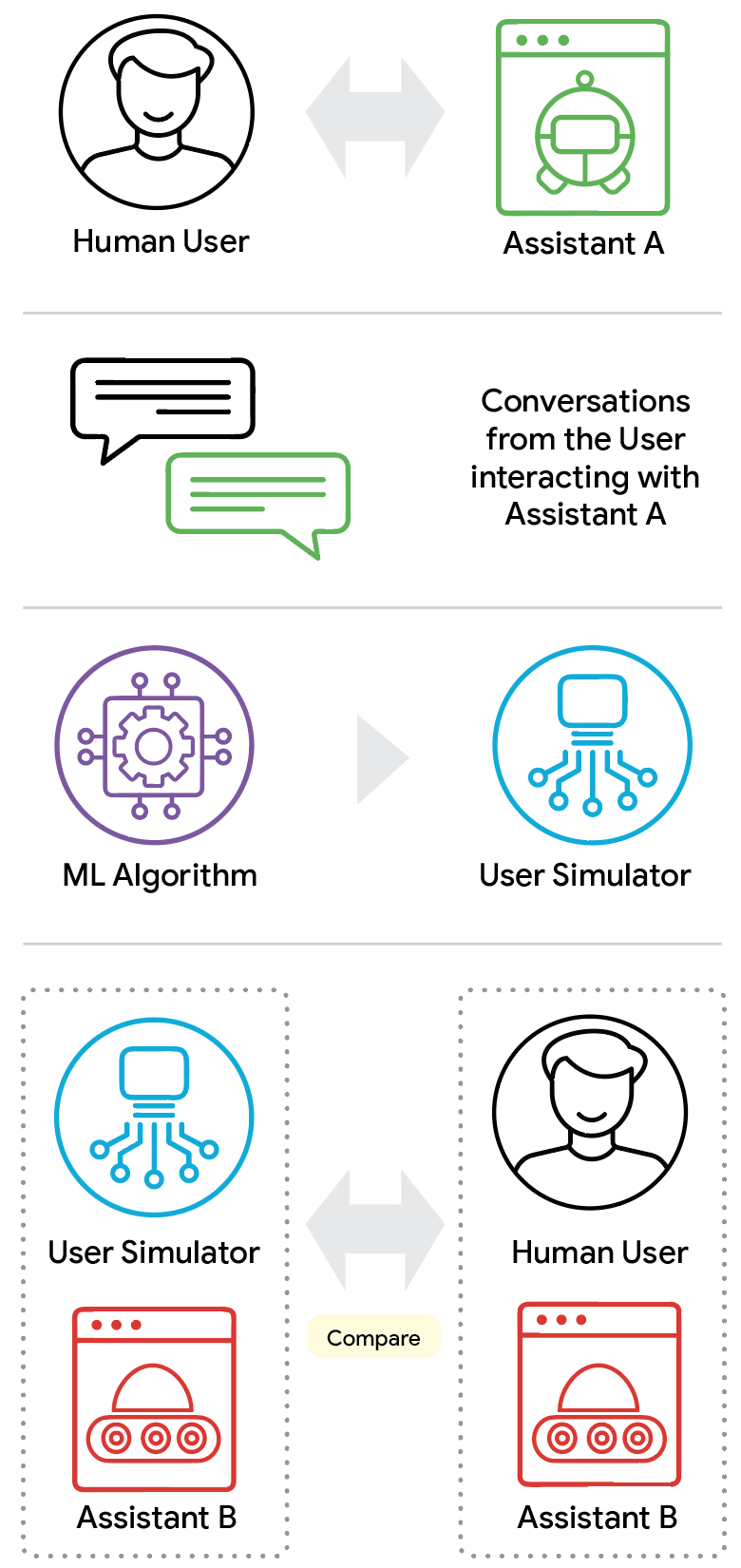
Google’s team ran a clever experiment. They routed real participants to either a helpful “Good” agent or an intentionally unhelpful “Bad” agent. The resulting dataset, ConvApparel, captures the full spectrum of human behavior—from satisfaction to profound annoyance. This is the kind of data we need.
Counterfactual validation: the clever bit
The paper introduces something called counterfactual validation, which is the most interesting methodological contribution here. The idea is simple: how would a simulated user react if it encountered a frustrating system that looked nothing like the helpful ones it learned from?
Most simulators fail this test. They’ve been trained on polite, cooperative interactions, so when faced with a deliberately bad agent, they either break character or respond in ways no real human ever would. It’s like a pilot simulator that only generates clear skies and gentle tailwinds.
Why this matters for conversational AI
If you’re training your conversational agent only against these unrealistic simulators, you’re going to ship a product that falls apart in the real world. Users will get frustrated, agents will fail to detect frustration, and the whole experience degrades.
The ConvApparel framework provides three validation pillars: population-level statistics (do the simulators match human distributions?), human-likeness scoring (do individual turns feel human?), and counterfactual validation (can they handle unexpected situations?).
This is higher quality validation than most teams are doing today. If you’re building conversational agents, you should be paying attention.
Practical takeaways
- Your current simulator is probably too nice. Real users are not.
- Counterfactual validation should be part of your evaluation pipeline.
- The ConvApparel dataset is a useful benchmark, but you’ll want to collect your own domain-specific data too.
The paper is worth reading. It’s one of the few that actually tries to measure the problem rather than just acknowledging it exists.
Comments (0)
Login Log in to comment.
Be the first to comment!